






Whisperのlarge-v3モデルでリアルタイム文字起こしをしてみる
はじめに
whisperに「large-v3」モデルが公開されていることに今更ながら気が付いたので、リアルタイム文字起こしをしてみたいと思います。
出来る限りリアルタイムにしたいので、実際に使用するのは「faster-Whisper」です。
なお、音声周りのプログラムは書いたことがないので、適切でない処理や記載があるかもしれません。ご了承ください。
whisperとfaster-whisperについて
whisper
Whisperは、OpenAIが開発した音声認識モデルです。多言語対応で、音声認識だけでなく、音声翻訳や言語識別も行うことができます。大規模かつ多様なデータセットで訓練されており、高精度の音声認識を実現しています。

faster-whisper
faster-whisperは、Whisperモデルをより高速かつ効率的に動作させるために最適化されたバージョンです。リアルタイム音声認識の性能向上を目指しており、遅延を減らしつつ高精度の認識を提供します。

PC環境
- OS: Windows 10
- CPU: Intel Core i9-12900K
- RAM: 32GB
- GPU:GeForce RTX4090
- Python: 3.10
必要なライブラリのインストール
プログラムを動作させるために、以下のライブラリをインストールします。
pip install numpy
pip install watchdog
pip install faster_whisper
pip install pyaudio作成したい機能
1.喋っている途中で文字起こしをする
2.喋っている途中だと文章が不完全な可能性があるので、喋り終わったら最新情報で更新する
3.できる限り早いレスポンス
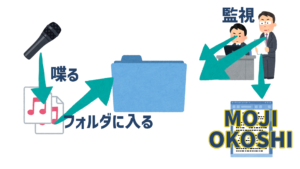
処理のイメージ
こんなイメージです。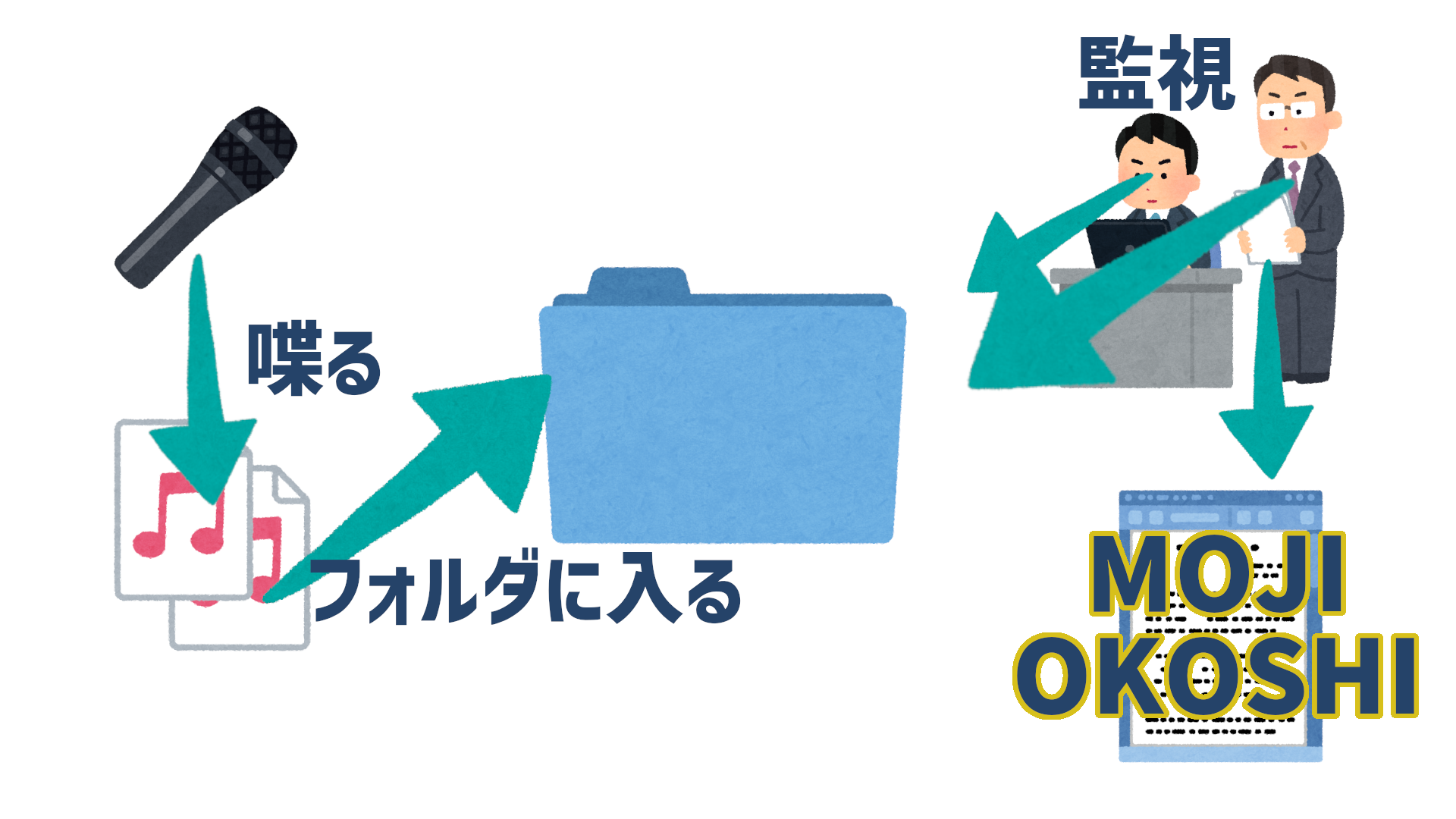
プログラムの説明
githubにも同じものを公開しています。

プログラム全体
録音と文字起こしを別スレッドで処理するようにしています。
録音側はただwavファイルを出力するだけ、文字起こし側はwavファイルの文字起こしと削除を行っています。
import os
import time
import numpy as np
from pathlib import Path
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
from threading import Thread
from faster_whisper import WhisperModel
import wave
import pyaudio
import concurrent.futures
HALLUCINATION_TEXTS = [
"ご視聴ありがとうございました", "ご視聴ありがとうございました。",
"ありがとうございました", "ありがとうございました。",
"どうもありがとうございました", "どうもありがとうございました。",
"どうも、ありがとうございました", "どうも、ありがとうございました。",
"おやすみなさい", "おやすみなさい。",
"Thanks for watching!",
"終わり", "おわり",
"お疲れ様でした", "お疲れ様でした。",
]
# モデルのロード
MODEL_SIZE = "large-v3"
model = WhisperModel(MODEL_SIZE, device="cuda", compute_type="float16")
# パラメータ設定
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
CHUNK = 1024
SILENCE_THRESHOLD = 10 # 無音判定のしきい値
SILENCE_DURATION = 0.2 # 無音判定する持続時間 (秒)
OUT_DURATION = 0.5 # 強制的に途中出力する時間(秒)
MIN_AUDIO_LENGTH = 0.1 # 最小音声長 (秒)
# PyAudioインスタンス作成
audio = pyaudio.PyAudio()
# ストリームの設定
stream = audio.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
executor = concurrent.futures.ThreadPoolExecutor(max_workers=2)
def record_audio(audio_directory):
frames = []
recording = False
silent_chunks = 0
speak_chunks = 0
speak_cnt = 1
audio_directory.mkdir(parents=True, exist_ok=True)
def is_silent(data):
# 無音かどうかを判定する関数
rms = np.sqrt(np.mean(np.square(np.frombuffer(data, dtype=np.int16))))
return rms < SILENCE_THRESHOLD
def save_wave_file(filename, frames):
# 録音データをWAVファイルとして保存する関数
with wave.open(str(filename), 'wb') as wf: # Pathオブジェクトを文字列に変換
wf.setnchannels(CHANNELS)
wf.setsampwidth(audio.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
while True:
data = stream.read(CHUNK)
silent = is_silent(data)
if silent:
silent_chunks += 1
speak_chunks = 0
else:
silent_chunks = 0
speak_chunks += 1
if silent_chunks > (SILENCE_DURATION * RATE / CHUNK):
if recording:
if len(frames) * CHUNK / RATE < MIN_AUDIO_LENGTH:
return
else:
# 無音状態が続いたら録音を停止してファイルを保存
file_path = audio_directory / f"recorded_audio_{file_name}_latest.wav"
executor.submit(save_wave_file, Path(file_path), frames)
frames = []
recording = False
speak_cnt = 1
else:
if not recording:
file_name = f"{int(time.time())}"
recording = True
if speak_chunks > (OUT_DURATION * RATE / CHUNK):
file_path = audio_directory / f"recorded_audio_{file_name}_{speak_cnt}.wav"
executor.submit(save_wave_file, Path(file_path), frames)
speak_cnt += 1
speak_chunks = 0
frames.append(data)
class FileHandler(FileSystemEventHandler):
def on_created(self, event):
if event.is_directory:
return
file_name, file_ext = os.path.splitext(event.src_path)
if not file_name.endswith("_latest"):
base_name = file_name.rsplit('_', 1)[0]
suffix = int(file_name.rsplit('_', 1)[-1])
if os.path.exists(os.path.join(os.path.dirname(event.src_path), f"{base_name}_latest.wav")):
# 最終ファイルがあるので処理不要、ファイル削除してスキップ
os.remove(event.src_path)
return
if os.path.exists(os.path.join(os.path.dirname(event.src_path), f"{base_name}_{suffix + 1}.wav")):
# 次ファイルがあるので処理不要、ファイル削除してスキップ
os.remove(event.src_path)
return
# 文字起こしして、ファイルを削除
self.process_file(event.src_path)
os.remove(event.src_path)
def process_file(self, file_path):
# 文字起こし
transcription = self.transcribe(file_path)
# ハルシネーションで出力された可能性のある場合は処理しない
if transcription in HALLUCINATION_TEXTS:
return
if transcription:
if "latest" in str(file_path):
# 最終ファイルの場合、そのまま出力
print(transcription)
else:
# 喋っている途中の文字起こしは《》で囲う
print("《"+transcription+"》")
def transcribe(self, file_path):
try:
with open(file_path, 'rb') as audio_file:
segments, _ = model.transcribe(audio_file, language="ja", beam_size=5, patience=0.5)
transcription = ''.join(segment.text for segment in segments)
return transcription
except Exception as e:
print(f"Error in transcribe: {e}")
return ""
def start_monitoring(watch_path):
# 録音処理(スレッドを立てる)
# wavファイルを生成し続ける処理
record_thread = Thread(target=record_audio, args=(watch_path,))
record_thread.daemon = True
record_thread.start()
# フォルダを監視してwavファイルが生成された場合
# 文字起こし処理を行う
event_handler = FileHandler()
observer = Observer()
observer.schedule(event_handler, watch_path, recursive=False)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
if __name__ == "__main__":
start_monitoring(Path.cwd() / "tmp")録音処理(record_audio)
録音中も一定期間ごとに、wavファイルを出力しています。喋り終わらないと文字起こしが実行されないのはリアルタイム感がないなぁと思ったので、喋り途中でも問答無用でwavファイルを出力する仕様にしました。
def record_audio(audio_directory):
frames = []
recording = False
silent_chunks = 0
speak_chunks = 0
speak_cnt = 1
audio_directory.mkdir(parents=True, exist_ok=True)
def is_silent(data):
# 無音かどうかを判定する関数
rms = np.sqrt(np.mean(np.square(np.frombuffer(data, dtype=np.int16))))
return rms < SILENCE_THRESHOLD
def save_wave_file(filename, frames):
# 録音データをWAVファイルとして保存する関数
with wave.open(str(filename), 'wb') as wf: # Pathオブジェクトを文字列に変換
wf.setnchannels(CHANNELS)
wf.setsampwidth(audio.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
while True:
data = stream.read(CHUNK)
silent = is_silent(data)
if silent:
silent_chunks += 1
speak_chunks = 0
else:
silent_chunks = 0
speak_chunks += 1
if silent_chunks > (SILENCE_DURATION * RATE / CHUNK):
if recording:
if len(frames) * CHUNK / RATE < MIN_AUDIO_LENGTH:
return
else:
# 無音状態が続いたら録音を停止してファイルを保存
file_path = audio_directory / f"recorded_audio_{file_name}_latest.wav"
executor.submit(save_wave_file, Path(file_path), frames)
frames = []
recording = False
speak_cnt = 1
else:
if not recording:
file_name = f"{int(time.time())}"
recording = True
if speak_chunks > (OUT_DURATION * RATE / CHUNK):
file_path = audio_directory / f"recorded_audio_{file_name}_{speak_cnt}.wav"
executor.submit(save_wave_file, Path(file_path), frames)
speak_cnt += 1
speak_chunks = 0
frames.append(data)文字起こし処理(フォルダ監視とtranscribe)
監視対象のフォルダにファイルが作成されたことを検知して、文字起こし処理を実行します。
喋り途中ファイルの場合は、現段階より先のwavファイルがない場合のみ処理を行います。
class FileHandler(FileSystemEventHandler):
def on_created(self, event):
if event.is_directory:
return
file_name, file_ext = os.path.splitext(event.src_path)
if not file_name.endswith("_latest"):
base_name = file_name.rsplit('_', 1)[0]
suffix = int(file_name.rsplit('_', 1)[-1])
if os.path.exists(os.path.join(os.path.dirname(event.src_path), f"{base_name}_latest.wav")):
# 最終ファイルがあるので処理不要、ファイル削除してスキップ
os.remove(event.src_path)
return
if os.path.exists(os.path.join(os.path.dirname(event.src_path), f"{base_name}_{suffix + 1}.wav")):
# 次ファイルがあるので処理不要、ファイル削除してスキップ
os.remove(event.src_path)
return
# 文字起こしして、ファイルを削除
self.process_file(event.src_path)
os.remove(event.src_path)
def process_file(self, file_path):
# 文字起こし
transcription = self.transcribe(file_path)
# ハルシネーションで出力された可能性のある場合は処理しない
if transcription in HALLUCINATION_TEXTS:
return
if transcription:
if "latest" in str(file_path):
# 最終ファイルの場合、そのまま出力
print(transcription)
else:
# 喋っている途中の文字起こしは《》で囲う
print("《"+transcription+"》")
def transcribe(self, file_path):
try:
with open(file_path, 'rb') as audio_file:
segments, _ = model.transcribe(audio_file, language="ja", beam_size=5, patience=0.5)
transcription = ''.join(segment.text for segment in segments)
return transcription
except Exception as e:
print(f"Error in transcribe: {e}")
return ""実行結果
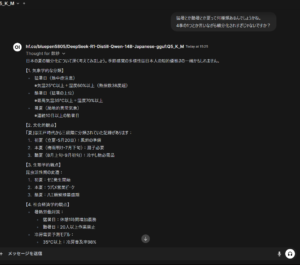
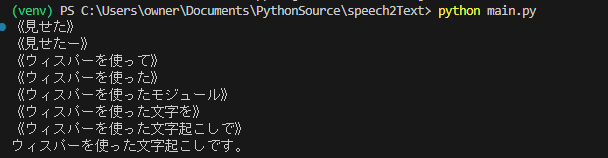
「whisperを使った文字起こしです」と発声してみました。
《》がついているものが途中経過です。喋り切っていないwavファイルを使用しているので、最初は全く違う言葉ですが徐々に正確になっていますね。
実際に使用する際には最終結果のみでいいかもですが、生放送とかで使用する場合は途中経過もあった方がよりリアル感が増しますね。
改善点
私の滑舌やイントネーションが悪いのか、認識しづらい文字はとことん認識しづらい印象でした。
ノイズ除去等の前処理を全く行っていないので、その辺を実装すると改善されるかも?しれません。
気が向いたらやってみようと思います。